从 Rust 库学 - hashbrown 的工作原理与具体实现
前言
hashbrown 是 SwissTable 的 Rust 实现,而 SwissTable 是 Google 在 CppCon 2017 上公开的一种更快的 HashTable。从 Rust 1.36 开始(2023.12.04 Rust stable 版本为 1.74.1),hashbrown 为 Rust HashMap/HashSet 的默认实现。
最近笔者研究 hashbrown 库出于以下的两件事情。
Arc<Mutex<HashMap<U, V>>>
在多线程并发下,经常会用到 Arc<Mutex<HashMap<U, V>>>,但这意味着每次读写 hashmap 都需要锁 mutex,对性能影响比较大。这个问题实际上是 实现高效的多线程并发 HashMap,有库 dashmap 实现了这一数据结构,笔者后面再单独研究后写文章来阐述。
C++ 标准库 unordered_map 慢
最近工作中的 C++ 项目跑 benchmark 发现 unordered_map 的 find 操作特别慢。而由于该业务处的 hashmap 比较稀疏,因此加了一段代码用来快速排除 find 结果。这个问题向外拓展是 有没有什么实现的比较快 HashMap。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15// 不用取模的 hash 函数,速度会比较快 int quickHash(U& u) { return u.hashCode & 0x7f; } void QuickHashTable::initialize(U& u) { // 初始化时构造 bitset this->bitset.set(quickHash(u), true); } V* QuickHashTable::find(U& u) { // 不包含则肯定不在 hashmap 里,可以直接返回 null if (!this->bitest.test(quickHash(u))) { return nullptr; } // ... 省略剩下的实现 }
AHash
由于介绍的是 HashTable,首先需要搞明白 如何衡量一个 hash 函数。一个 hash 函数可以通过以下方面衡量:
- 性能
- hash 小对象的速度:如
uint64 - hash 大对象的速度:如 1kb 的
string - 占用内存
- hash 小对象的速度:如
- 质量
- DDOS 攻击防御:在已知种子的情况下,能否构造一组数据使得都 hash 为同一个值
- 是否存在 bad seeds:使用这些种子会导致 DDOS 攻击
- 是否存在未定义行为 (Undefined Behaviour, UB)
SMhasher 测试套件 可以用来测试 hash 函数的性能和质量。
AHash 是 hashbrown 默认的 hash 函数,它的速度非常快,对 DDOS 的防御有限,被设计在内存中使用。
以下是 AHash 在 hash u64 时在 fallback_hash.rs 中的部分实现,其中只使用同余乘法、异或、位移等操作来实现。对于 AHash 的 hash 质量,笔者功力不足无法理解,或许搞 CTF 的同学更能看得懂(所谓术业有专攻)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15///This constant comes from Kunth's prng (Empirically it works better than those from splitmix32). pub(crate) const MULTIPLE: u64 = 6364136223846793005; pub(crate) const fn folded_multiply(s: u64, by: u64) -> u64 { let result = (s as u128).wrapping_mul(by as u128); ((result & 0xffff_ffff_ffff_ffff) as u64) ^ ((result >> 64) as u64) } impl AHasher { // ... #[inline(always)] fn update(&mut self, new_data: u64) { self.buffer = folded_multiply(new_data ^ self.buffer, MULTIPLE); } }
一些前置知识
三角数 mod
hashbrown 内部用的不是 拉链法,而是 基于 三角数 (杨辉三角每一行的中间数)的探测法。
假设 i = hash(x),那么 hashbrown 会依次访问大小为 N 的数组的第 i % N, (i + 1) % N, (i + 1 + 2) % N, (i + 1 + 2 + 3) % N, ... 位。可以证明,访问 N 次时,恰好访问且仅访问了数组中的每一位一次。
由于 i 只是偏移量,可以简单的令 i = 0,则 0, 1, 3, 6, ... 构成三角数(杨辉三角每一行的中间数)。这相当于证明 从第 个到第 个三角数 mod 构成 到 的一个排列数。
文章 Triangular numbers mod 2^n 给出了详细的证明,笔者这里根据自己对这篇文章的理解给出证明。
令
性质 1: 在 与 之间处对称,即 ,证明:
另外,这里有
性质 2: 的循环节为 ,证明:
性质 3: 当 n 为 2 次方时, 从 到 时 为 至 的一个排列,使用递推证明:
定义 ,当 从 到 时 为 至 的一个排列,那么
因此对于 从 到 , 的值为 或 。又因为
所以 与 在同余下相差 。当 从 到 时 包含了 至 的一个排列以及 至 的一个排列,正好是 至 的一个排列。
一些通用的位运算
删掉最后一位 1
1x & (x - 1)
很好理解,将 x 表述为 ...10000...000,x - 1 为 ...01111...111,相与最后 1 位变为 0。
最后一位 1 的位置
本质上是个二分算法,但直接用 trailing_zeros 计算(C++ 用 __builtin_ctz),编译器可能会翻译为 CPU 指令,性能会高出很多。
hashbrown 中的一些位运算
由于还没有介绍 hashbrown 的原理,笔者这里换一种方式介绍背景。
现在有一个 u8 的数组,其中的值只可能是 0x80, 0x8f 或 0x00 至 0x7f 中的任何数。我们可能从数组的任意位置视为 u32 将数据读出来做运算。
将 0x80, 0xff 转为 0x80,剩下的转为 0x00
直接和 0x80808080 相与。
1x & u32::from_ne_bytes(0x80)
将 0xff 转为 0x80,剩下的转为 0x00
实际上是判断最高位和次高位为 1。让自己与自己左移一位相与,再与 0x80,结果为 0x80 说明最高位和次高位都为 1。
1x & (x << 1) & u32::from_ne_bytes(0x80)
将指定的 y 转为 0x80,剩下的转为 0x00
操作 (t - 1) & ~t 能得到取最低位 1 再减 1 的结果,当 t = 0 时结果为 0xff,是唯一能让最高位为 1 的值。所以先异或 x,再应用这个操作,最后直接与 0x80。
1 2let z = x ^ u32::from_ne_bytes(y); z.wrapping_sub(repeat(0x01)) & !z & repeat(0x80)
将 0x80 转为 0xff,0xff 保持 0xff,其他转为 0x80
首先将自己取反后与 0x80 相与,这样 0x80 与 0xff 会转为 0x00,其他会转为 0x80。再取最高位后加上取反的结果,那么 0x00 会变为 0x7f,0x80 会变为 0x80。
1 2let y = !x & repeat(0x80); !y + (y >> 7)
hashbrown 的工作原理
注意
本部分阐述 hashbrown 工作原理,其中查找、插入、删除等操作会附加伪代码,这些伪代码并不是 hashbrown 中的真实实现,hashbrown 中的实现会考虑性能因素,具体见 “hashbrown 的具体实现”。
内存布局
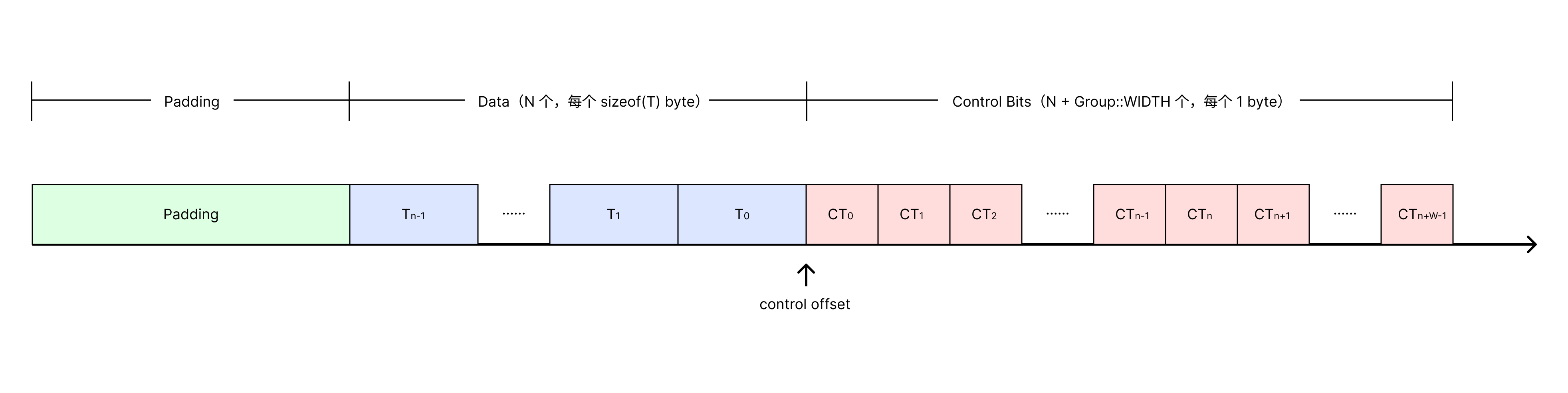
一个桶大小为 n 的 hashbrown 的内存布局如上图所示,被分为 3 个部分:
- Padding: 最前面的部分,目的是让后面的 control offset 处在内存对齐的位置
- Data: 存放真实数据,这里注意数据是逆序存放的
- Control Bits: 控制位,control offset 是控制位的起始位置, 与 对应,反映了 的特征,也反映了存在与否
这里的 n 一定是 2 的幂。
h1, h2 函数
hashbrown 中定义了 h1, h2 函数:
h1(x):hash(x)h2(x):(hash(x) >> (8 * sizeof(usize) - 7)) & 0x7f,即取高 7 位
h1 决定了数据存放的位置,h2 决定了数据的特征值。具体的,如果插入 x 且能够插入,那么:
x所在的位置i为h1(x) % n- 为
x - 为
h2(x)
顺带一提,这里和 SwissTable 的定义不太一样,SwissTable 定义了 h1 是高 57 位,h2 是低 7 位,和 hashbrown 刚好反过来。
Control Bits
控制位段是 hashbrown 中用于快速检索的设计,有三种状态:
- EMPTY: 代表空,值为
0xff - DELETED: 代表被删除,值为
0x80 - FULL: 代表有值,值的范围为
[0x00, 0x7f],由h2(x)计算得到
由于每个控制位占 1 个字节,所以可以在数据位段中将某一段视为 u32, u64 甚至 u128 进行查找。这一段在 hashbrown 里被称为 Group,Group 中的字节数记录在了 Group::WIDTH 上。有了 Group 加上上文介绍的位运算,能够根据需要过滤得到数据位中 FULL, DELETED, EMPTY 的位置。
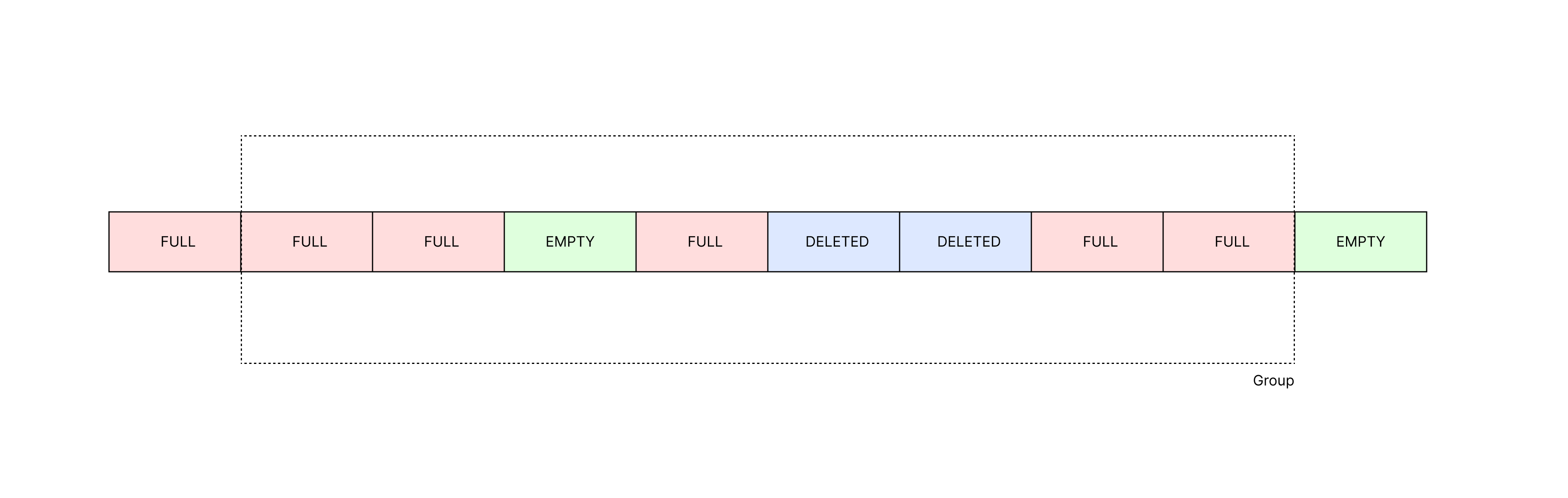
控制位结尾多出来的 Group::WIDTH 个字节与前 Group::WIDTH 字节对应,具体的,。这样的设计是为了 Group 查询时以周期的方式查询。
这里还要考虑一种例外的情况,当 n < Group::WIDTH 时,控制位结尾的 n 个字节与前 n 个字节对应,中间的 Group::WIDTH - n 个字节都是 EMPTY。
初始化
假设要初始化大小为 size,类型为 T = (K, V) 的表,则:
- 保证
size一定是 2 的幂:- 计算
h1(x) % size可以转为h1(x) & (size - 1),避免非常慢的取模运算 - 需要利用 “三角形 mod ” 的结论
- 计算
- 计算剩余容量,保证表中一定有至少 1 个 EMPTY 项,剩余容量只用于控制扩容与 rehash:
- 若
size < 8,则剩余容量取size - 1,保留 1 个 EMPTY 项 - 若
size >= 8,则剩余容量取 ,保留 12.5% 的 EMPTY 项,用于控制 load factor
- 若
- 计算内存布局并分配内存:
- 计算 control 在内存的对齐大小
control_align:由于T和Group都要对齐,所以取max(sizeof(T), Group::WIDTH) - 计算 control bit 的偏移
control_offset: - 分配内存
control_offset + size + Group::WIDTHbytes
- 计算 control 在内存的对齐大小
- 将控制位段全部初始化位
0xff
从上面的操作可以知道 hashbrown 的一些特性:
size一定是 2 的幂- 表中一定有至少 1 个 EMPTY 项
这些特性在接下来的插入、删除等操作中会用到。
查找 key
首先计算 key 在表中对应的开始探测位置 pos 与控制位:
1 2pos = h1(key) % size h2_hash = h2(key)
这样在位置 pos 加载 Group。
如果 Group 中找到了匹配项,那么返回 value。这个操作需要找到 Group 中与 h2_hash 相同的位,得到他们的位置,再把数据段中的真实数据取出来比较是否真的与 key 一致。
如果 Group 中没有找到匹配项,那么:
- 如果 Group 中存在 EMPTY 项,则直接返回不存在,这是没有找到匹配项的唯一终止条件。
- 否则,按三角数偏移 pos 移动到下个 Group 继续查找。
整个查找过程没有额外的终止条件,即查找过程要么找到 key 一致的项并返回 value,要么找到 EMPTY 返回不存在。这要求表里一定要存在 EMPTY 项,而初始化时保证了表里一定有 EMPTY 项。
由于每次探测时都取一整个 Group,这里基于三角数的偏移实际上需要乘上 Group::WIDTH,即偏移量依次为 Group::WIDTH, 3 * Group::WIDTH, 6 * Group::WIDTH。为什么这样也是正确的?由于探测时 Group::WIDTH < BucketSize,Group::WIDTH 与 BucketSize 又都是 2 的幂,因此整个探测得到的各个 Group 任意两个之间不会重叠,可以把 Group 看成一个整体,这样就又回到了纯粹的基于三角数偏移的探测中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37T find(key) { data_index = find_index(key) if data_index == null { return null } else { return load_data(data_index).value } } Index find_index(key) { pos = h1(key) % size h2_hash = h2(key) loop_count = 0 loop forever { group = load_group(pos) foreach bit in group.match(h2_hash) { data_index = (pos + bit) % size if load_data(data_index).key == key { return data_index } } if group.has_empty() { return null } loop_count += 1 pos = next_group_pos(pos, loop_count) } } Index next_group_pos(pos) { pos = (pos + loop_count * Group::WIDTH) % size }
插入 (key, value)
按查找中相同的计算得到 pos 与 h2_hash,并加载 Group。
如果在 Group 中找到了 key 匹配的项,那么替换掉 value。
如果在 Group 中没有找到 key 匹配的项,那么移动到下个 Group 继续查找,直到 Group 内有一个 EMPTY 项。
如果在整个过程中都没有找到 key 匹配的项,那么插入的位置为所有加载过的 Group 中第一个为 EMPTY 或 DELETED 的项的位置,在这个位置上插入 value。
特别的,若 size < Group::WIDTH,由于超过 size 的部分初始值为 EMPTY,所以得到的插入的位置可能是非法的,需要重新从第一个 Group 中加载一个 EMPTY 或 DELETED 的位置。
当得到了插入的位置后,可以直接写入数据,并写入控制位 h2_hash。特别的,若 index < Group::WIDTH,那么在 index + size 也写入相同的控制位 h2_hash,这是为了处理循环节问题,即 Group 起点位于最后 Group::WIDTH 项的情况。不仅是插入操作,所以更改控制位的操作都需要做这个维护。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42Void insert(key, value) { // ... data_index = find_index(key) if data_index == null { // 没找到,那么找 EMPTY 或 DELETED data_index = find_empty_or_deleted_index(key) } // 一定能找到,最不济都会是 EMPTY 项的位置 assert(data_index != null) store_data(data_index, Item { key, value }) h2_hash = h2(key) store_control_bit(data_index, h2_hash) } Index find_empty_or_deleted_index(key) { pos = h1(key) % size loop_count = 0 loop { group = load_group(pos) if group.has_empty_or_deleted() { bit = group.lowest_empty_or_deleted() data_index = (pos + bit) % size return data_index } loop_count += 1 pos = next_group_pos(pos, loop_count) } } Void store_control_bit(index, hash) { bits[index] = hash if index < Group::WIDTH { bits[index + size] = hash } }
删除 key
执行查找 key 的操作找到对应的位置,然后标记为 DELETED 即可。
但如果能够进一步标记为 EMPTY,那么可以为后续的 查找、插入、删除 提高性能。要标记为 EMPTY 就不能改变查询终止条件,即查询到 Group 内存在 EMPTY 时就需要终止,即任何包含 DELETED 的 Group 中都包含至少一个 EMPTY。这样的 EMPTY 必然至少有一个存在于 DELETED 的左侧,有一个存在于 DELETED 的右侧。
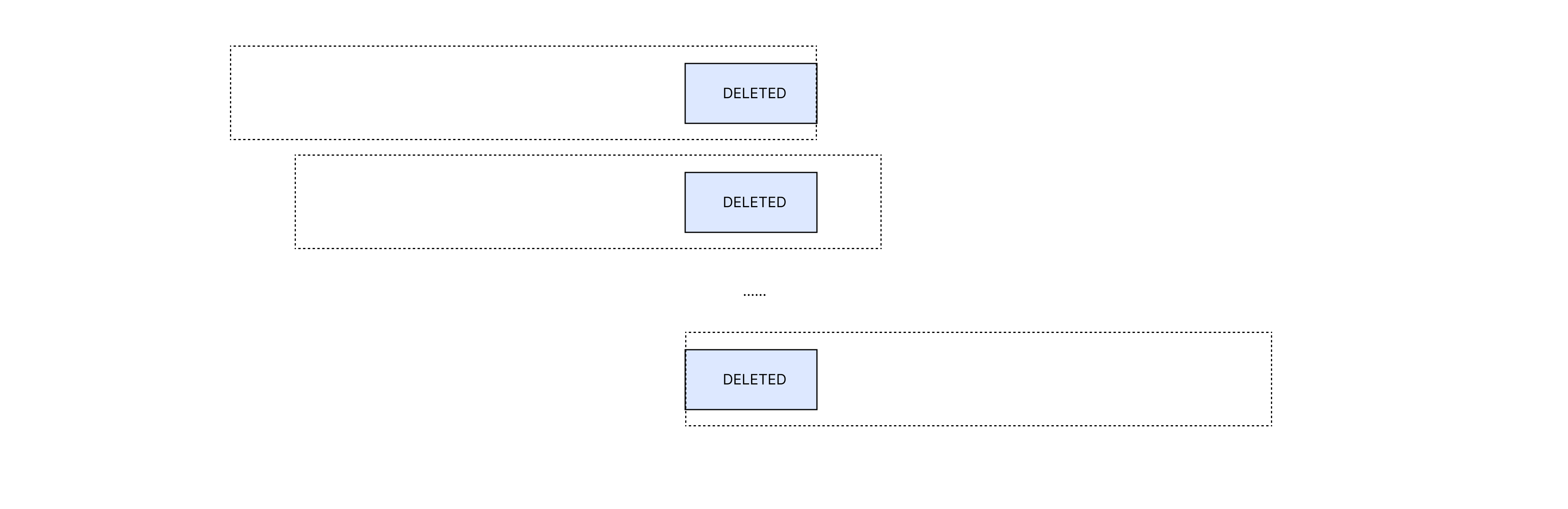
我们把左侧的 DELETED 位置记为 x,对 Group 按左端点排序,显然 Group 左侧在 x 左侧的都覆盖到了,而右侧的 EMPTY 最远可以放在 x + GROUP::WIDTH - 1 来覆盖全部的 Group。这相当于要求 DELETED 的位置向左向右延生最多有非 EMPTY 元素 GROUP::WIDTH - 1 个。这样可以把前后两个 Group 加载出来,对 EMPTY 做与运算后统计前导与后导 0 的个数统计出来。
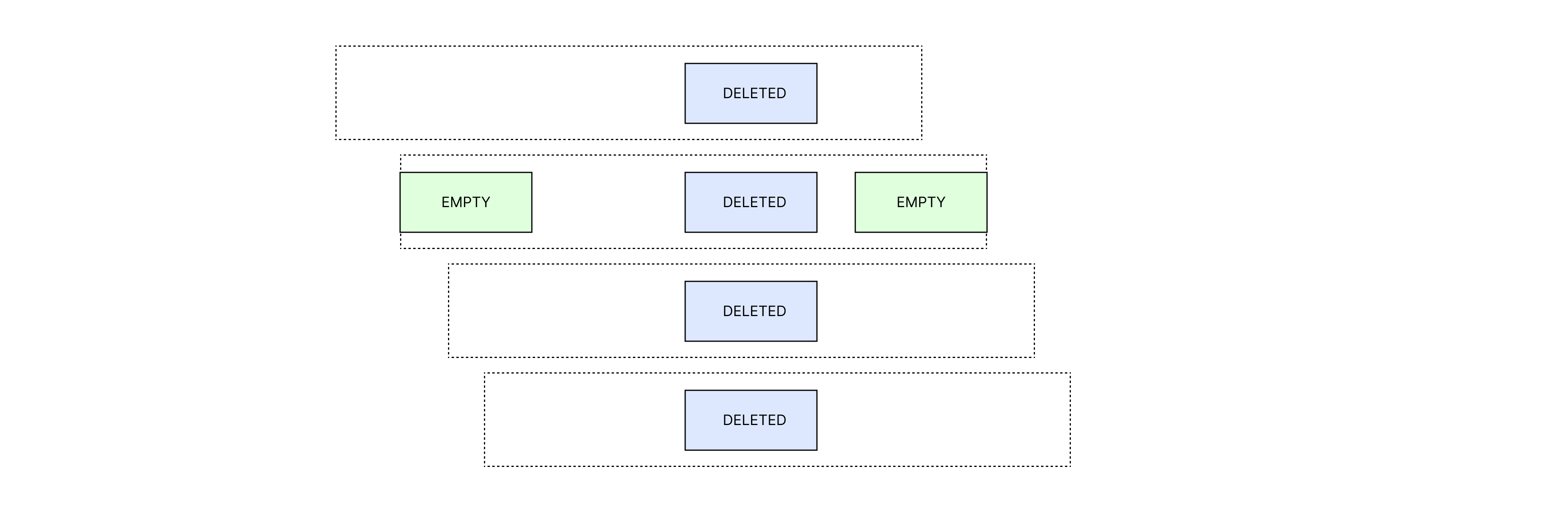
特别的,如果 size < Group::WIDTH,根据上面的优化,表中一定不存在 DELETE。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17Void remove(index) { assert(load_control(index) == FULL) index_before = index if index >= Group::WIDTH { index_before = index - Group::WIDTH } group_before = load_group(index_before) group = load_group(index) if suffix_zeros(group_before.match_empty()) + prefix_zeros(group.match_empty()) >= Group::WIDTH { store_control_bit(index, DELETED) } else { store_control_bit(index, EMPTY) } }
扩容、缩容
执行插入操作时,若剩余容量为 0,且正好剩下的 FULL 项超过了容量的 ,那么执行扩容操作:
- 构造新的表,新的容量取
- 遍历旧表的 FULL 项,计算出新的位置并写入控制位,再复制数据
- 最后记录新的表的已有大小与剩余容量
缩容操作在 hashbrown 中并不会主动执行,需要使用者主动调用执行,其原理实际上就是扩容的原理,通过重新构造表实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16Void resize(new_bucket_size) { // 创建新表 let mut new_table = create_new_table(new_bucket_size) for full_byte_index in full_buckets_indices() { let hash = hash(load_data(full_byte_index).key); new_index = new_table.find_empty_index(hash); new_table.store_data(new_index, load_data(new_index)) new_table.store_control_bit(new_index, h2(hash)) } new_table.growth_left -= len(); new_table.items = len(); swap(self, new_table) }
Rehash
执行插入操作时,若剩余容量为 0,且 FULL 项没有超过容量的 ,那么说明表中的 DELETED 项太多了,执行 rehash 操作。rehash 操作会将表中的 DELETED 改为 EMPTY,并移动 FULL 的位置使之满足 hashbrown 的要求,这可以提升查找性能。
具体的:
- 预处理:在控制位段上,把 FULL 改为 DELETE,DELETE 改为 EMPTY
- 顺序遍历 DELETED 位。假设当前位置为
i
2.1. 重新计算i位置的数据的 hash 并照查找算法得到新的位置new_i
2.2. 若i与new_i不在以 hash 开头的同一个 Group 里- 若
new_i这个位置上现在是 EMPTY,则将数据复制过去,并设置为 FULL,继续 步骤 2。这相当于添加到 Group 中。 - 若
i这个位置上现在是 DELETE,那么交换数据,并设置new_i为 FULL,继续 步骤 2.1。这相当于将 Group 中原有的项先复制出来,再将现在的数据添加进 Group,最后重新处理这个原有项。
i与new_i在以 hash 开头的同一个 Group 里,那么直接设置i位置上的控制位为 FULL 即可。这是因为:i < new_i是不可能发生的,因为new_i是第一个可以被插入的位置,而i是 DELETED 是可以被插入的,所以一定满足i <= new_i- 若
i == new_i,那么改控制位为 FULL 即可 - 若
i > new_i,因为 1.2 中的算法最终不会产生或移动 DELETED 项,只会产生 FULL 或 EMPTY 项,可以知道如果已经遍历到i,那么任意小于i的项都已经被处理了,一定只会是 FULL 或 EMPTY,这里new_i又是一个可以插入的位置,所以一定是 EMPTY。这里可以不和 EMPTY 交换,因为不会影响查询和后续的插入操作
- 若
- 最后维护剩余容量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40fn rehash() { foreach group in groups() { group.convert_deleted_to_empty_and_full_to_deleted() } foreach i in buckets() { if load_control(i) != DELETED { continue; } loop { key = load_data(i).key h2_hash = h2(key) new_i = find_empty_or_deleted_index(hash); if is_in_same_group(i, new_i, h2_hash) { store_control_bit(i, hash) break } new_i_control_bit = load_control(new_i) if prev_ctrl == EMPTY { store_data(new_i, load_data(i)) store_control_bit(new_i, h2_hash) store_control_bit(i, EMPTY) break } else { assert(new_i_control_bit == DELETED) new_i_data = load_data(new_i) store_data(new_i, load_data(i)) store_control_bit(new_i, h2_hash) store_data(i, new_i_data) } } } growth_left = buckets().len() - len(); }
hashbrown 的具体实现
概述
这个部分更多的是对 hashbrown 源码的解读,笔者将 hashbrown 中的核心实现挑出来解读,并会忽略一些非主流程的代码(并非不重要),如 T 类型大小为 0 的特殊处理。笔者有兴趣的话,可以将 hashbrown 代码 clone 下来阅读,其中包含了不少代码注释,甚至是包含了编译为 LLVM IR 时的考量。
BitMask
BitMask 用于加载 Group 计算的结果,提供遍历方法。
1 2 3 4 5 6 7 8 9 10 11 12 13#[derive(Copy, Clone)] pub(crate) struct BitMask(pub(crate) BitMaskWord); impl Iterator for BitMaskIter { type Item = usize; #[inline] fn next(&mut self) -> Option<usize> { let bit = self.0.lowest_set_bit()?; self.0 = self.0.remove_lowest_bit(); Some(bit) } }
在构造 BitMask 时 byte 只会是 0x80 或 0x00,且保证是小端序(little endian),如
1BitMask((self.0 & (self.0 << 1) & repeat(0x80)).to_le())
这样 BitMask 能提供前导 0 与后导 0 的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40// 1 字节 8 位 pub(crate) const BITMASK_STRIDE: usize = 8; #[derive(Copy, Clone)] pub(crate) struct BitMask(pub(crate) BitMaskWord); cfg_if! { if #[cfg(any( target_pointer_width = "64", target_arch = "aarch64", target_arch = "x86_64", target_arch = "wasm32", ))] { type GroupWord = u64; } else { type GroupWord = u32; } } pub(crate) type BitMaskWord = GroupWord; impl BitMask { #[inline] pub(crate) fn trailing_zeros(self) -> usize { // 源代码这里解释了为什么 ARM 下要这么写 if cfg!(target_arch = "arm") && BITMASK_STRIDE % 8 == 0 { self.0.swap_bytes().leading_zeros() as usize / BITMASK_STRIDE } else { // 因为只有 0x80 与 0x00,所以除以 8 // 0x80 末尾 7 个 0,统计为 0 // 0x00 末尾 8 个 0,统计为 1 self.0.trailing_zeros() as usize / BITMASK_STRIDE } } #[inline] pub(crate) fn leading_zeros(self) -> usize { self.0.leading_zeros() as usize / BITMASK_STRIDE } }
Group
Group 顾名思义,用于加载 Group 的处理。有通用的位运算处理实现,基于 x86 SSE2 的处理,ARM NEON 的处理实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32impl Group { // 在软件实现下,Group::WIDTH 取的是内存地址的大小 pub(crate) const WIDTH: usize = mem::size_of::<Self>(); #[inline] pub(crate) fn match_byte(self, byte: u8) -> BitMask { let cmp = self.0 ^ repeat(byte); BitMask((cmp.wrapping_sub(repeat(0x01)) & !cmp & repeat(0x80)).to_le()) } #[inline] pub(crate) fn match_empty(self) -> BitMask { BitMask((self.0 & (self.0 << 1) & repeat(0x80)).to_le()) } #[inline] pub(crate) fn match_empty_or_deleted(self) -> BitMask { BitMask((self.0 & repeat(0x80)).to_le()) } #[inline] pub(crate) fn match_full(self) -> BitMask { self.match_empty_or_deleted().invert() } // EMTPY, DELETED 转 EMPTY,FULL 转 DELETED #[inline] pub(crate) fn convert_special_to_empty_and_full_to_deleted(self) -> Self { let full = !self.0 & repeat(0x80); Group(!full + (full >> 7)) } }
TableLayout
TableLayout 用于记录类型 T 的内存布局的字节数,以及 control 的内存对齐大小。当给定桶的数量后,可以计算总的内存布局以及 control_offset,用于分配内存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41#[derive(Copy, Clone)] struct TableLayout { size: usize, ctrl_align: usize, } impl TableLayout { #[inline] const fn new<T>() -> Self { let layout = Layout::new::<T>(); Self { size: layout.size(), // 既要 T 对齐,又要 Group 对齐 ctrl_align: if layout.align() > Group::WIDTH { layout.align() } else { Group::WIDTH }, } } // 计算总的内存布局与 control_offset #[inline] fn calculate_layout_for(self, buckets: usize) -> Option<(Layout, usize)> { debug_assert!(buckets.is_power_of_two()); let TableLayout { size, ctrl_align } = self; // 相当于 ceil((size * buckets) / ctrl_align) * ctrl_align let ctrl_offset = size.checked_mul(buckets)?.checked_add(ctrl_align - 1)? & !(ctrl_align - 1); // 总大小 = ctrl_offset + 控制位段的大小 let len = ctrl_offset.checked_add(buckets + Group::WIDTH)?; // ... Some(( unsafe { Layout::from_size_align_unchecked(len, ctrl_align) }, ctrl_offset, )) } }
Bucket
Bucket 是存储 T 类型具体数据的桶,其中包含指向内存地址末尾的指针 ptr。这里指向末尾是为了方便根据下标获取桶,获取桶的下标等,读取的时候从内存地址开始的位置读。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41pub struct Bucket<T> { // 指向数据地址的末尾,而不是开头 ptr: NonNull<T>, } impl<T> Bucket<T> { // 根据下标获取桶 #[inline] unsafe fn from_base_index(base: NonNull<T>, index: usize) -> Self { // ... // 因为内存布局中数据段是倒过来的,这里用减法 let ptr = base.as_ptr().sub(index); Self { ptr: NonNull::new_unchecked(ptr), } } // 获取桶的下标 #[inline] unsafe fn to_base_index(&self, base: NonNull<T>) -> usize { // ... offset_from(base.as_ptr(), self.ptr.as_ptr()) } // 获取桶内部数据的地址 #[inline] pub fn as_ptr(&self) -> *mut T { // 返回内存地址开头 unsafe { self.ptr.as_ptr().sub(1) } } #[inline] pub(crate) unsafe fn read(&self) -> T { self.as_ptr().read() } #[inline] pub(crate) unsafe fn write(&self, val: T) { self.as_ptr().write(val); } }
InsertSlot
InsertSlot 表示可以插入的位置,插入时需要用记录的桶的下标找到 bucket。
1 2 3pub struct InsertSlot { index: usize, }
ProbeSeq
ProbeSeq(Probe sequence),用作于探测序列的迭代器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19struct ProbeSeq { // 当前的位置,每次探测会加上 stride pos: usize, // 步长,每次探测会加上 Group::WIDTH,形成 (三角数 * Group::WIDTH) stride: usize, } impl ProbeSeq { #[inline] fn move_next(&mut self, bucket_mask: usize) { // 最多探测 (bucket_mask / Group::WIDTH) 次就会遍历到每一个 Group,超过了说明已经探测不到了 // 但由于表中一定存在 EMPTY,所以不应该超过 debug_assert!(self.stride <= bucket_mask, "Went past end of probe sequence"); self.stride += Group::WIDTH; self.pos += self.stride; self.pos &= bucket_mask; } }
RawTable
RawTable 是 HashMap, HashSet 内部的核心,表达 hash 表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24pub struct RawTable<T, A: Allocator = Global> { // 无模板参数的核心 table table: RawTableInner, // allocator alloc: A, marker: PhantomData<T>, } impl<T, A: Allocator> RawTable<T, A> { // 类型 T 的 TableLayout const TABLE_LAYOUT: TableLayout = TableLayout::new::<T>(); } struct RawTableInner { // bucket 数量减 1(因为 bucket 数量一定是 2 的幂) bucket_mask: usize, // ctrl_offset 的位置 ctrl: NonNull<u8>, // 表剩余容量 growth_left: usize, // 表中 FULL 项的数量 items: usize, }
初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142// 容量转为桶数量 #[cfg_attr(target_os = "emscripten", inline(never))] #[cfg_attr(not(target_os = "emscripten"), inline)] fn capacity_to_buckets(cap: usize) -> Option<usize> { debug_assert_ne!(cap, 0); // 比较小的表,保留 1 个 EMPTY 项 if cap < 8 { return Some(if cap < 4 { 4 } else { 8 }); } // 保留 12.5% 个 EMPTY 项 let adjusted_cap = cap.checked_mul(8)? / 7; Some(adjusted_cap.next_power_of_two()) } // 桶数量转为容量,实际上是 capacity_to_buckets 的逆 #[inline] fn bucket_mask_to_capacity(bucket_mask: usize) -> usize { if bucket_mask < 8 { // 桶数量 - 1 bucket_mask } else { // 桶数量 * (1 - 12.5%) ((bucket_mask + 1) / 8) * 7 } } impl RawTableInner { // 创建未初始化 control 的 RawTable #[cfg_attr(feature = "inline-more", inline)] unsafe fn new_uninitialized<A>( alloc: &A, table_layout: TableLayout, buckets: usize, fallibility: Fallibility, ) -> Result<Self, TryReserveError> where A: Allocator, { // buckets 必须是 2 的幂 debug_assert!(buckets.is_power_of_two()); // 计算总的内存布局与 control offset let (layout, ctrl_offset) = match table_layout.calculate_layout_for(buckets) { Some(lco) => lco, None => return Err(fallibility.capacity_overflow()), }; // 分配内存 let ptr: NonNull<u8> = match do_alloc(alloc, layout) { Ok(block) => block.cast(), Err(_) => return Err(fallibility.alloc_err(layout)), }; // control 的开始位置 let ctrl = NonNull::new_unchecked(ptr.as_ptr().add(ctrl_offset)); Ok(Self { ctrl, bucket_mask: buckets - 1, items: 0, growth_left: bucket_mask_to_capacity(buckets - 1), }) } // 创建 RawTable,考虑内存分配 panic #[inline] fn fallible_with_capacity<A>( alloc: &A, table_layout: TableLayout, capacity: usize, fallibility: Fallibility, ) -> Result<Self, TryReserveError> where A: Allocator, { if capacity == 0 { Ok(Self::NEW) } else { unsafe { let buckets = capacity_to_buckets(capacity).ok_or_else(|| fallibility.capacity_overflow())?; // 先创建未初始化的表 let result = Self::new_uninitialized(alloc, table_layout, buckets, fallibility)?; // 初始化 contrl 为 EMPTY (0xff) result.ctrl(0).write_bytes(EMPTY, result.num_ctrl_bytes()); Ok(result) } } } // 创建 RawTable,认为内存分配已经处理了 panic fn with_capacity<A>(alloc: &A, table_layout: TableLayout, capacity: usize) -> Self where A: Allocator, { match Self::fallible_with_capacity(alloc, table_layout, capacity, Fallibility::Infallible) { Ok(table_inner) => table_inner, // hint::unreachable_unchecked 用于告知编译器这个分支不会走到,编译器可能会做一些优化 Err(_) => unsafe { hint::unreachable_unchecked() }, } } // 获取第 index 个 control 的值 #[inline] unsafe fn ctrl(&self, index: usize) -> *mut u8 { debug_assert!(index < self.num_ctrl_bytes()); self.ctrl.as_ptr().add(index) } } // RawTable 的初始化基本上是透传到 RawTableInner impl<T, A: Allocator> RawTable<T, A> { const TABLE_LAYOUT: TableLayout = TableLayout::new::<T>(); #[cfg_attr(feature = "inline-more", inline)] unsafe fn new_uninitialized( alloc: A, buckets: usize, fallibility: Fallibility, ) -> Result<Self, TryReserveError> { debug_assert!(buckets.is_power_of_two()); Ok(Self { table: RawTableInner::new_uninitialized( &alloc, Self::TABLE_LAYOUT, buckets, fallibility, )?, alloc, marker: PhantomData, }) } pub fn with_capacity_in(capacity: usize, alloc: A) -> Self { Self { table: RawTableInner::with_capacity(&alloc, Self::TABLE_LAYOUT, capacity), alloc, marker: PhantomData, } } }
查找
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42impl<T, A: Allocator> RawTable<T, A> { // eq 函数能够对比桶中记录的值是否匹配,一般是 (key,value) 中的 key 是否一致 #[inline] pub fn find(&self, hash: u64, mut eq: impl FnMut(&T) -> bool) -> Option<Bucket<T>> { let result = self.table.find_inner(hash, &mut |index| eq(self.bucket(index).as_ref())); match result { Some(index) => Some(self.bucket(index)), None => None, } } } impl RawTableInner { #[inline(always)] unsafe fn find_inner(&self, hash: u64, eq: &mut dyn FnMut(usize) -> bool) -> Option<usize> { let h2_hash = h2(hash); let mut probe_seq = self.probe_seq(hash); loop { let group = unsafe { Group::load(self.ctrl(probe_seq.pos)) }; // 找到匹配 h2(hash) 的位置,看看是否一致 for bit in group.match_byte(h2_hash) { let index = (probe_seq.pos + bit) & self.bucket_mask; // 一致则找到了 // 这里 likely 是告知编译器分支预测很可能为 true if likely(eq(index)) { return Some(index); } } // 当前 Group 里存在 EMPTY,那么不用继续探测,肯定不存在 if likely(group.match_empty().any_bit_set()) { return None; } probe_seq.move_next(self.bucket_mask); } } }
插入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126impl<T, A: Allocator> RawTable<T, A> { // 查找已有项,如果没有则返回 InsertSlot #[inline] pub fn find_or_find_insert_slot( &mut self, hash: u64, mut eq: impl FnMut(&T) -> bool, hasher: impl Fn(&T) -> u64, ) -> Result<Bucket<T>, InsertSlot> { // 至少容量需要剩下 1,否则 扩容 或 rehash self.reserve(1, hasher); unsafe { match self .table .find_or_find_insert_slot_inner(hash, &mut |index| eq(self.bucket(index).as_ref())) { Ok(index) => Ok(self.bucket(index)), Err(slot) => Err(slot), } } } // 将值插入到 InsertSlot 中 #[inline] pub unsafe fn insert_in_slot(&mut self, hash: u64, slot: InsertSlot, value: T) -> Bucket<T> { let old_ctrl = *self.table.ctrl(slot.index); self.table.record_item_insert_at(slot.index, old_ctrl, hash); // 写入 let bucket = self.bucket(slot.index); bucket.write(value); bucket } } impl RawTableInner { #[inline] unsafe fn find_or_find_insert_slot_inner( &self, hash: u64, eq: &mut dyn FnMut(usize) -> bool, ) -> Result<usize, InsertSlot> { // 可以插入的位置,类型为 Option<usize> let mut insert_slot = None; let h2_hash = h2(hash); let mut probe_seq = self.probe_seq(hash); loop { let group = unsafe { Group::load(self.ctrl(probe_seq.pos)) }; for bit in group.match_byte(h2_hash) { let index = (probe_seq.pos + bit) & self.bucket_mask; if likely(eq(index)) { return Ok(index); } } // 如果 insert_slot 是空的,那么找这个 Group 内的 EMPTY 或 DELETED 的位置(可能找不到) // 这里 insert_slot 只设置一次,是因为只需要取最开始探测到的 EMPTY 或 DELETED 的位置 // 后面的探测是为了查找值是否存在 if likely(insert_slot.is_none()) { insert_slot = self.find_insert_slot_in_group(&group, &probe_seq); } // 如果 Group 内存在 EMPTY,那么探测结束,返回 insert_slot if likely(group.match_empty().any_bit_set()) { unsafe { // 这里 insert_slot 一定存在,因为最不济会取到这个 Group 中的 EMPTY。 // 特别的,若 bucket_mask + 1 < Group::WIDTH,那么 insert_slot 可能是错的, // 因为超过 bucket_mask 的部分虽然是越界的,但是他们也是 EMPTY,取到他们会得到 // index & bucket_mask 的结果 return Err(self.fix_insert_slot(insert_slot.unwrap_unchecked())); } } probe_seq.move_next(self.bucket_mask); } } // 当桶数量 <= Group::WIDTH 时,修正 index #[inline] unsafe fn fix_insert_slot(&self, mut index: usize) -> InsertSlot { // 当桶数量 <= Group::WIDTH 时,index 指向的可能是非法的,如果非法值是 EMPTY 或 DELETED,那么刚好就用这个位置; // 如果是 FULL,那么重新加载 if unlikely(self.is_bucket_full(index)) { debug_assert!(self.bucket_mask < Group::WIDTH); // 因为 index 无效,直接加载第一个 Group 中的 EMPTY 或 DELETED 项 index = Group::load_aligned(self.ctrl(0)) .match_empty_or_deleted() .lowest_set_bit() .unwrap_unchecked(); } InsertSlot { index } } // 插入 InsertSlot 时维护控制位段 #[inline] unsafe fn record_item_insert_at(&mut self, index: usize, old_ctrl: u8, hash: u64) { // 如果是 EMPTY 则剩余容量减少 1 self.growth_left -= usize::from(special_is_empty(old_ctrl)); self.set_ctrl_h2(index, hash); self.items += 1; } // 根据 hash 设置控制位 #[inline] unsafe fn set_ctrl_h2(&mut self, index: usize, hash: u64) { self.set_ctrl(index, h2(hash)); } // 根据 h2_hash 设置控制位 #[inline] unsafe fn set_ctrl(&mut self, index: usize, ctrl: u8) { // 若 index < Group::WIDTH,index2 = index + bucket_mask + 1 // 若 index >= Group::WIDTH,index2 = index // 这里这样写是为了避免写 if let index2 = ((index.wrapping_sub(Group::WIDTH)) & self.bucket_mask) + Group::WIDTH; *self.ctrl(index) = ctrl; *self.ctrl(index2) = ctrl; } }
删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45impl<T, A: Allocator> RawTable<T, A> { #[cfg_attr(feature = "inline-more", inline)] #[allow(clippy::needless_pass_by_value)] pub unsafe fn remove(&mut self, item: Bucket<T>) -> (T, InsertSlot) { self.erase_no_drop(&item); ( item.read(), InsertSlot { index: self.bucket_index(&item), }, ) } #[cfg_attr(feature = "inline-more", inline)] unsafe fn erase_no_drop(&mut self, item: &Bucket<T>) { let index = self.bucket_index(item); self.table.erase(index); } } impl RawTableInner { // 擦除第 index 个桶 #[inline] unsafe fn erase(&mut self, index: usize) { debug_assert!(self.is_bucket_full(index)); // index 前面的一个桶 // 若 bucket_mask + 1 <= Group::WIDTH,那么 index_before = index let index_before = index.wrapping_sub(Group::WIDTH) & self.bucket_mask; let empty_before = Group::load(self.ctrl(index_before)).match_empty(); let empty_after = Group::load(self.ctrl(index)).match_empty(); // 由于是 BitMask 返回小端模式的结果, // 所以 empty_before.leading_zeros() 是 index 往前(不包括自己)连续非 EMPTY 的个数, // empty_after.trailing_zeros() 是 index 往后连续非 EMPTY 的个数 let ctrl = if empty_before.leading_zeros() + empty_after.trailing_zeros() >= Group::WIDTH { DELETED } else { self.growth_left += 1; EMPTY }; self.set_ctrl(index, ctrl); self.items -= 1; } }
Rehash 与扩容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248impl<T, A: Allocator> RawTable<T, A> { #[cfg_attr(feature = "inline-more", inline)] pub fn reserve(&mut self, additional: usize, hasher: impl Fn(&T) -> u64) { // 如果剩余容量不够 additional,那么考虑 rehash 或扩容 if unlikely(additional > self.table.growth_left) { unsafe { if self .reserve_rehash(additional, hasher, Fallibility::Infallible) .is_err() { hint::unreachable_unchecked() } } } } #[cold] #[inline(never)] unsafe fn reserve_rehash( &mut self, additional: usize, hasher: impl Fn(&T) -> u64, fallibility: Fallibility, ) -> Result<(), TryReserveError> { unsafe { self.table.reserve_rehash_inner( &self.alloc, additional, &|table, index| hasher(table.bucket::<T>(index).as_ref()), fallibility, Self::TABLE_LAYOUT, if T::NEEDS_DROP { Some(mem::transmute(ptr::drop_in_place::<T> as unsafe fn(*mut T))) } else { None }, ) } } } impl RawTableInner { #[allow(clippy::inline_always)] #[inline(always)] unsafe fn reserve_rehash_inner<A>( &mut self, alloc: &A, additional: usize, hasher: &dyn Fn(&mut Self, usize) -> u64, fallibility: Fallibility, layout: TableLayout, drop: Option<fn(*mut u8)>, ) -> Result<(), TryReserveError> where A: Allocator, { // 假设有另外 additional 个 FULL 项 let new_items = match self.items.checked_add(additional) { Some(new_items) => new_items, None => return Err(fallibility.capacity_overflow()), }; let full_capacity = bucket_mask_to_capacity(self.bucket_mask); if new_items <= full_capacity / 2 { // 表中 FULL 项没有超过了容量的一半,但是 EMPTY 项却没有 additional 个,那么就说明 DELETE 项太多了,做 rehash self.rehash_in_place(hasher, layout.size, drop); Ok(()) } else { // 否则,确实需要扩容 self.resize_inner( alloc, usize::max(new_items, full_capacity + 1), hasher, fallibility, layout, ) } } // rehash 前的准备 // DELETED, EMPTY 转为 EMPTY,FULL 转为 DELETED #[allow(clippy::mut_mut)] #[inline] unsafe fn prepare_rehash_in_place(&mut self) { for i in (0..self.buckets()).step_by(Group::WIDTH) { let group = Group::load_aligned(self.ctrl(i)); let group = group.convert_special_to_empty_and_full_to_deleted(); group.store_aligned(self.ctrl(i)); } // 处理最后 Group::WIDTH 个控制位 if unlikely(self.buckets() < Group::WIDTH) { self.ctrl(0) .copy_to(self.ctrl(Group::WIDTH), self.buckets()); } else { self.ctrl(0) .copy_to(self.ctrl(self.buckets()), Group::WIDTH); } } // rehash #[allow(clippy::inline_always)] #[cfg_attr(feature = "inline-more", inline(always))] #[cfg_attr(not(feature = "inline-more"), inline)] unsafe fn rehash_in_place( &mut self, hasher: &dyn Fn(&mut Self, usize) -> u64, size_of: usize, drop: Option<fn(*mut u8)>, ) { // 非 FULL 转为 EMPTY,FULL 转为 DELETED self.prepare_rehash_in_place(); // 如果 hasher panic 了,那么下面的回调会执行 // 如果有 drop 方法,此时 DELELTED 是还没有 rehash 的部分,标记为 EMPTY 然后清除掉 // 最后维护剩余容量 let mut guard = guard(self, move |self_| { if let Some(drop) = drop { for i in 0..self_.buckets() { if *self_.ctrl(i) == DELETED { self_.set_ctrl(i, EMPTY); drop(self_.bucket_ptr(i, size_of)); self_.items -= 1; } } } self_.growth_left = bucket_mask_to_capacity(self_.bucket_mask) - self_.items; }); // 此时需要处理所有的 DELETED,按顺序遍历第 i 个桶 'outer: for i in 0..guard.buckets() { if *guard.ctrl(i) != DELETED { continue; } let i_p = guard.bucket_ptr(i, size_of); 'inner: loop { let hash = hasher(*guard, i); // 计算 rehash 后应该放入的位置 let new_i = guard.find_insert_slot(hash).index; // 如果 i 与 new_i 都在以 hash 开头的 Group 内,那么无需插入,只重新设置控制位 if likely(guard.is_in_same_group(i, new_i, hash)) { guard.set_ctrl_h2(i, hash); continue 'outer; } let new_i_p = guard.bucket_ptr(new_i, size_of); // 否则,把 i 插入到 new_i 这个位置上,并看 new_i 这个位置上的原本的控制位 let prev_ctrl = guard.replace_ctrl_h2(new_i, hash); if prev_ctrl == EMPTY { // 如果是 EMPTY,把 i 挪动到 new_i 的位置上,自己设置为空 guard.set_ctrl(i, EMPTY); ptr::copy_nonoverlapping(i_p, new_i_p, size_of); continue 'outer; } else { // 否则只可能是 DELETED,需要把 i 挪动到 new_i 的位置上后,继续处理 new_i 位置上原本的项 debug_assert_eq!(prev_ctrl, DELETED); ptr::swap_nonoverlapping(i_p, new_i_p, size_of); continue 'inner; } } } guard.growth_left = bucket_mask_to_capacity(guard.bucket_mask) - guard.items; // 这里需要避免 guard 的回调被执行,因为它只在 panic 时执行 mem::forget(guard); } // resize 前准备 #[allow(clippy::mut_mut)] #[inline] fn prepare_resize<'a, A>( &self, alloc: &'a A, table_layout: TableLayout, capacity: usize, fallibility: Fallibility, ) -> Result<crate::scopeguard::ScopeGuard<Self, impl FnMut(&mut Self) + 'a>, TryReserveError> where A: Allocator, { debug_assert!(self.items <= capacity); // 创建新的 RawTableInner let new_table = RawTableInner::fallible_with_capacity(alloc, table_layout, capacity, fallibility)?; // hasher 发生 panic 时,bucket_mask != 0,此时满足 !self_.is_empty_singleton(),会手动把剩下的桶也清除掉 Ok(guard(new_table, move |self_| { if !self_.is_empty_singleton() { unsafe { self_.free_buckets(alloc, table_layout) }; } })) } // 找到 InsertSlot,先设置控制位 #[inline] unsafe fn prepare_insert_slot(&mut self, hash: u64) -> (usize, u8) { let index: usize = self.find_insert_slot(hash).index; let old_ctrl = *self.ctrl(index); self.set_ctrl_h2(index, hash); (index, old_ctrl) } // resize #[allow(clippy::inline_always)] #[inline(always)] unsafe fn resize_inner<A>( &mut self, alloc: &A, capacity: usize, hasher: &dyn Fn(&mut Self, usize) -> u64, fallibility: Fallibility, layout: TableLayout, ) -> Result<(), TryReserveError> where A: Allocator, { // 创建新表 let mut new_table = self.prepare_resize(alloc, layout, capacity, fallibility)?; for full_byte_index in self.full_buckets_indices() { let hash = hasher(self, full_byte_index); // 找到 InsertSlot,设置控制位 let (new_index, _) = new_table.prepare_insert_slot(hash); // 拷贝数据 ptr::copy_nonoverlapping( self.bucket_ptr(full_byte_index, layout.size), new_table.bucket_ptr(new_index, layout.size), layout.size, ); } // 维护剩余容量与已有项 new_table.growth_left -= self.items; new_table.items = self.items; // 交换两张表 mem::swap(self, &mut new_table); Ok(()) } }
后言
本文目前至少缺失了两个部分:
- hashbrown 性能为什么这么高?
- SIMD 部分
不管有没有缺失,笔者依然建议读者自己把 hashbrown 的代码 clone 下来阅读,其中包含了作者的不少注释。
以下是废话:
hashbrown 是笔者工作这两年见过的写的最精炼的算法,没有之一。无论是其中对于 if 语句的避免,还是对于 LLVM IR 的考量,对于使用 dynamic dispatch 的考量等等。阅读 hashbrown 的实现不一定会对平时的编码有直接的帮助,更多的是无形之中的帮助。整个 hahsbrown 的实现,或者说 SwissTable 的设计,给笔者一种很熟悉的以前搞 ACM 的感觉,这是笔者第一次发现 ACM 算法思维在工程界上有如此大的应用。所以说,即使工作了也要偶尔写写题,就像以前师兄说的:“我们学的东西有技术壁垒,一般人一时半会搞不懂”。